

Investigadores de las universidades de Granada (UGR) y Cambridge (Reino Unido) han advertido de la necesidad de establecer diferentes subclases de Trastorno del Espectro Autista (TEA) más homogéneas que las que se emplean en la actualidad, para poder comprender mejor la enfermedad y alcanzar una mayor precisión para detectar el autismo.
Los científicos han utilizado técnicas de neuroimagen, como la Resonancia Magnética (RM) para evaluar y detectar el autismo, ya que han descubierto que existen ciertas carencias en el método que se utiliza actualmente para tal fin.
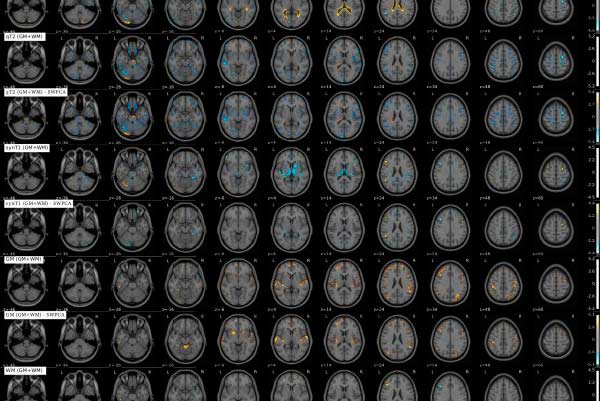
La investigación, realizada por el grupo de investigación SiPBA (Signal Processing and Biomedical Applications) de la UGR, destaca la gran cantidad de falsos diagnósticos positivos en las áreas cerebrales afectadas por TEA que se realizan en la actualidad, debido a las limitaciones derivadas del uso de RM para este fin, ya que las imágenes obtenidas en diferentes centros de diagnóstico poseen diferencias sustanciales, lo que hace que no sean comparables.
Establecer subclases de autismo
Los investigadores proponen que se subdivida el autismo en subclases para poder estudiarlo y comprenderlo mejor, en lugar de agruparlo como ha hecho el DSM-5 (el manual para diagnóstico de enfermedades psiquiátricas denominado American Psychiatric Association’s (APA) Diagnostic and Statistical Manual of Mental Disorders, que se emplea en la actualidad).
Pese a todos los intentos por homogeneizar estas bases de datos de imágenes, las diferencias existentes entre tipo de escáner, sesgo de pacientes, modelos, y otras características técnicas, suelen hacer que el resultado de los análisis se vea afectado por una gran cantidad de falsos positivos. Éstos aparecen de forma más evidente cuando las diferencias debidas a la enfermedad son sutiles, como es el caso del TEA, siendo prácticamente imposible distinguir cuáles son debidos a diferencias en la adquisición y cuáles son debidos a la enfermedad en sí misma.
Un método estadístico para diagnosticar el autismo
Para solucionar este problema, los investigadores han desarrollado un método estadístico llamado SWPCA (Significance Weighted Principal Component Analysis), que descompone los escáneres cerebrales como una combinación lineal de unas “componentes” que modelan las posibles fuentes de variabilidad en las imágenes cerebrales. Después, analizaron cuáles de estas posibles fuentes eran debidas o no a la enfermedad o a diferencias de adquisición, y eliminaron estas últimas. De esta forma, una vez eliminada esta variabilidad, realizaron un análisis exhaustivo, obteniendo resultados mucho más precisos.
Como explica el investigador de la UGR Francisco J. Martínez, perteneciente al departamento de Teoría de la Señal, Telemática y Telecomunicaciones de la UGR y uno de los autores del trabajo, “nuestro análisis concluye que, una vez eliminada la variabilidad en la adquisición, las diferencias entre afectados y no afectados por el TEA son muy poco relevantes, o bien que los patrones de esta enfermedad son demasiado heterogéneos como para poder ser considerada globalmente”.
Martínez señala que en el método para detectar el autismo SWPCA “la base de datos es descompuesta de forma que las imágenes se representan como una combinación lineal de valores o scores y componentes o loadings, que modelan la variabilidad existente en dicha base de datos. Al extraer un set de loadings común, podemos ver cuáles de estas componentes se relacionan con el lugar de adquisición, mediante unos test que resultan en un valor de significancia estadística, o p-value. Utilizando estos valores podemos reconstruir la base de datos cancelando parcial o totalmente la contribución de las componentes relacionadas con las diferencias entre lugares de adquisición, obteniendo una base de datos más homogénea y directamente analizable”.
Base de datos
Los investigadores han conseguido cancelar los efectos del lugar de adquisición en una base de datos de RM de pacientes con TEA, adquirida en varias sedes del Reino Unido, y examinar qué diferencias encontraron en esta base de datos corregida.
Tras ello, han concluido que las diferencias entre afectados y controles no eran relevantes, y que probablemente la mayoría de los estudios realizados con esta y otras bases de datos (como se ha comprobado también por otros estudios) estén afectados por este problema, donde los falsos positivos de TEA tienen como causa, en parte, diferencias entre los lugares de adquisición.












{kind=link}